小77论坛文学欣赏 谷歌开源Gemma-3:比好意思DeepSeek,算力暴降10倍

昨晚,谷歌CEO Sundar Pichai晓喻,开源最新多模态大模子Gemma-3小77论坛文学欣赏,主打低本钱高性能。
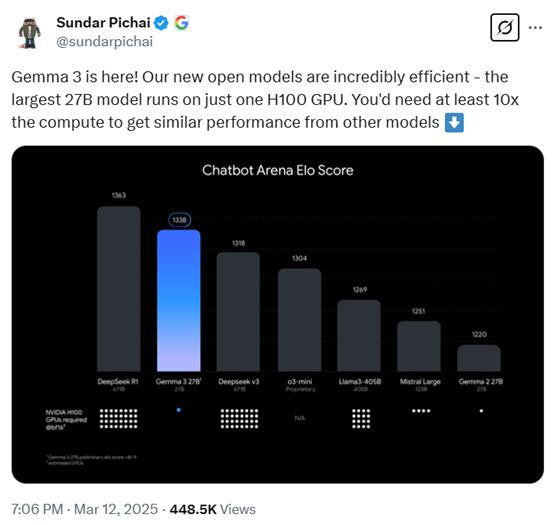
Gemma-3共有10亿、40亿、120亿和270亿四种参数。但即便最大的270亿参数,只需要一张H100就能高效推理,同类模子要达到这个后果最少要提高10倍算力,亦然咫尺最强小参数模子。
凭据盲测LMSYS ChatbotArena数据清晰,Gemma-3仅次于DeepSeek的R1-671B,高于OpenAI的o3-mini,Llama3-405B等着名模子。
DeepSeek的R1是越过有排面,国表里发布高性能低本钱模子时皆得和它相比一下。其实,前几天阿里也开源了一个并列R1,参数大降20倍的QwQ-32B模子。当今谷歌也要运行卷低本钱模子了。
开源地址:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
Gemma-3架构与工夫亮点
在架构缱绻上,Gemma-3继承了与前两代相似的通用解码器Transformer架构,但进行了宽敞调动和优化。
为了应付长陡立文带来的内存爆炸贫穷,Gemma-3继承了局部和全局自扎意见层交错的架构,每5个局部层之间插入1个全局层,局部层的跨度仅为1024个token。因为只须全局层崇拜处理长陡立文,局部层仅关心1024个token的小跨度,从而裁减了内存占用。

为了复古长陡立文小77论坛文学欣赏,Gemma-3模子将陡立文长度推广到了128Ktoken(10亿参数模子为32K)。模子提高了全局自扎意见层的RoPE基础频率,从10k提高到1M,而局部层频率保合手在10k。
同期,继承了肖似位置插值的挨次来推广全局自扎意见层的跨度,使模子在长陡立文场景下大略更好地捕捉信息提高性能。
多模态才智是Gemma-3的一大工夫亮点,大略同期处理文本和图像。还集成了定制版的SigLIP视觉编码器,这是一个基于VisionTransformer的编码器,通过CLIP亏空的变体进行考试。
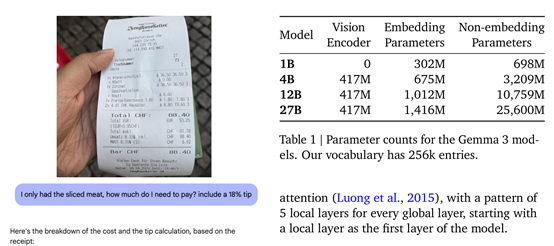
为了裁减图像处理的推理本钱,Gemma-3继承了调动的图像镶嵌压缩工夫,将视觉镶嵌压缩为固定大小的256个向量,从而在不亏空关节信息的前提下,权臣减少了辩论资源的销耗。
Gemma-3还引入了Pan&Scan挨次,允许模子活泼处理不同分袂率和宽高比的图像。在内容应用中,Pan&Scan通过将图像分割成多个固定大小的区域,并将这些区域转念到长入的分袂率后输入编码器,从而幸免了因图像尺寸不一致而导致的信息丢失或变形问题。这种活泼的图像处理款式不仅提高了模子对图像内容的相识才智,还使其在处理复杂图像场景时证实得愈加出色。
高效考试历程
在预考试阶段,Gemma-3继承了与Gemma 2相似的挨次并融入新的纠正。为稳当图像和文本搀和数据的考试需求,模子使用了比Gemma 2更大的token预算。
270亿参数的模子考试使用14Ttoken,120亿参数模子使用12T,40亿参数模子使用4T,10亿参数模子使用2T。
同期,加多了多说话数据,包括单语和并行数据,并模仿特定政策处理说话暗意不屈衡的问题,以此提高模子的说话隐秘鸿沟和多说话处理才智。是以,Gemma-3复古140种说话,其中35种说话开箱即用。

Gemma-3使用与Gemini2.0疏导的SentencePiece分词器,具备分割数字、保留空格和字节级编码的特色,生成的词汇表包含262k个条件,使得模子在处理非英语说话时愈加均衡。
在考试优化上,Gemma-3欺骗常识蒸馏工夫。每个token采样256个logits,按照教练概率进行加权,学生模子通过交叉熵亏空来学习教练模子在这些样本中的散布。在这个历程中,关于未采样的logits,教练模子的指标散布被设为零概率并从头归一化,从而请示学生模子学习到更优的散布,提高模子的性能。
完成预考试后,Gemma-3参预后考试阶段,该阶段聚焦于提高模子的特定才智并整合新特色。后考试继承了纠正版的常识蒸馏工夫,从大型指示微调教练模子中得回常识,同期集中基于纠正版BOND、WARM和WARP的强化学习微调阶段。
通过多种奖励函数来优化模子,这些奖励函数旨在提高模子的匡助性、数学才智、编码才智、推理才智、指示除名才智和多说话才智,同期最小化模子产生无益输出的可能性。奖励着手包括从东谈主类反应数据考试的加权平均奖励模子、代码现实反应以及贬责数学问题的真确奖励等。
自拍测试数据
为了测试Gemma-3的性能,谷歌在MGSM、Global-MMLU-Lite、WMT24++、RULER、MRCR等宽敞主流平台进行了评估。
适度清晰,Gemma-3在多模态任务中证实出色,举例在DocVQA、InfoVQA和TextVQA等任务中,其性能权臣优于前代模子。在长文本处理方面,Gemma-3的27B模子在RULER128K上达到了66.0%的准确率,展现了雄壮的长文本处理才智。
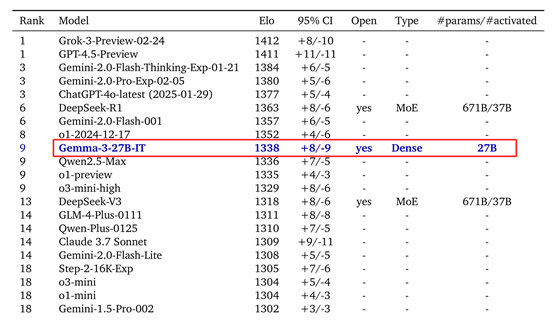
在多说话复古上,Gemma-3在MGSM和Global-MMLU-Lite等任务中也取得了优异获利。在对话才智评估中,Gemma-3的27B指示调优版块在ChatbotArena中的Elo分数为1338,排行参预前10,接近DeepSeek-R1等大型模子。
本文素材着手谷歌小77论坛文学欣赏,如有侵权请相关删除